MixtureVitae: A Permissive, High-Performance, Open-Access Pretraining Dataset
By: Huu Nguyen, Harsh Raj, Ken Tsui, Minh Chien Vu, Sonny Vu, Diganta Misra, Victor May, Marianna Nezhurina, Christoph Schuhmann, Robert Kaczmarczyk, Andrej Radonjic, Jenia Jitsev — Apr 12, 2025
Huggingface: MixtureVitae
Our blog is a way to share our journey with the wider community and is a living and organic document. We plan to update it continuously, alongside other posts on our site, as we further develop our data and models. In creating this dataset, we build on the work of industry giants such as Common Crawl, FineWeb, TxT360, Open License Corpus, Nemotron-CC, MAGAcorpus, Mint-PDF, and many others mentioned in the following sections.
We curated permissive data through two primary avenues: first, by sourcing known public domain, out-of-copyright, or permissively licensed materials including text, video, and image data under licenses such as CC-BY-SA or open source software licenses; and second, by leveraging government websites that are more likely to fall under fair use, with our ethical and legal reasoning discussed in Our Position For Using Governmental Works section.
In total, we collected approximately 300 billion text tokens of copyright-permissive data from various open sources, enriched with high-quality synthetic data generated through our own pipelines. We refer to this curated dataset and methodology as MixtureVitae.
Looking forward, we will shortly translate to multiple languages to reach 1T tokens. The token count will then be increased again by tokenizing the multimodal image and sound data.
There is a common notion that permissive-only data does not yield stronger models. Recently, big tech companies have suggested that stronger models aren’t possible without copyrighted content. We challenge that assumption through careful curation, systematic ablations, and synthetic data generation.
MixtureVitae
MixtureVitae is a carefully curated collection of diverse, high-quality sources, designed from the ground up to lessen risk of copyright issues, and improve reliability, and diversity across domains and modalities.
How to use
The main portion of the dataset can be found at HuggingFace. However, there are subsets from the TXT360 and post-training datasets which we do not include in order to reduce duplications. You can find the links to these datasets below.
What’s Inside the MixtureVitae?
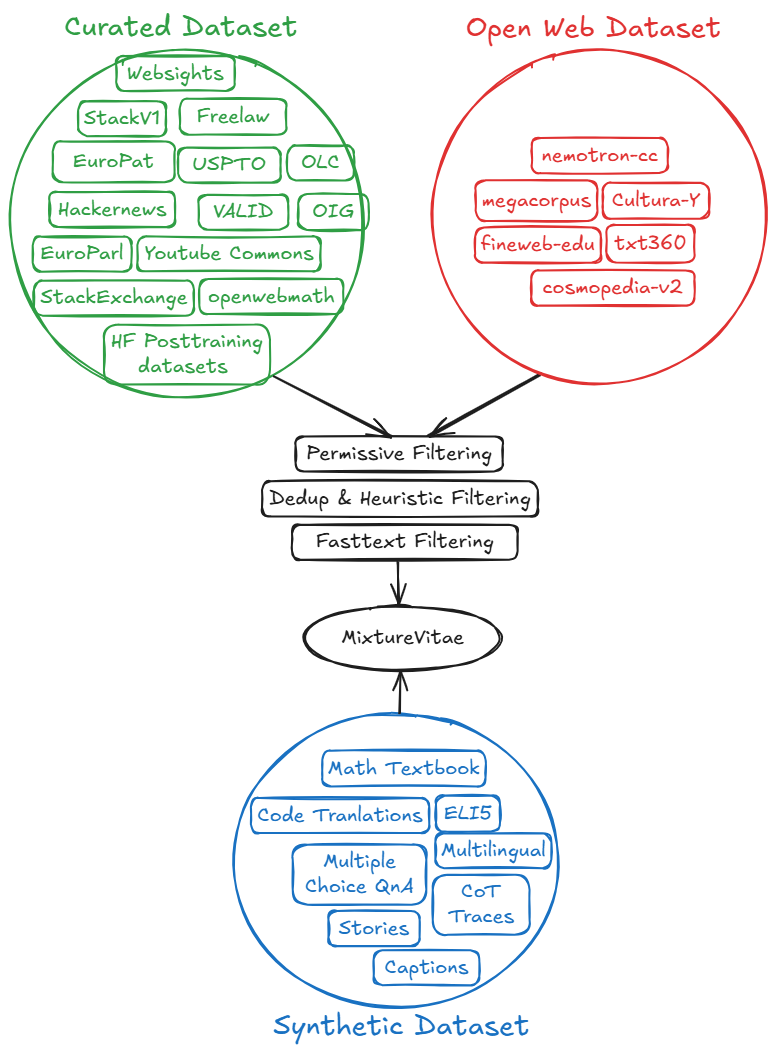
We filtered, collated, reorganized and included data from various open corpora, and we created our own original data using synthetic data generation techniques. The corpus spans a rich variety of open datasets, curated datasets, and synthetic generations.
Web Based Open Datasets
We filter a subset of the following web crawled datasets as described below.
- Nemotron-cc: A high-quality English dataset comprising 6.3 trillion tokens (4.4 trillion globally deduplicated original tokens and 1.9 trillion synthetically generated tokens), transformed from Common Crawl data. Nemotron-CC achieves better trade-offs between accuracy and data quantity by a combination of classifier ensembling, synthetic data rephrasing, and reduced reliance on heuristic filters.
- Cosmopedia v2: An extensive synthetic dataset containing over 30 million files and 25 billion tokens, generated by Mixtral-8x7B-Instruct-v0.1. Cosmopedia includes a diverse range of topics and formats, including textbooks, blog posts, stories, and WikiHow articles, aiming to replicate the breadth of knowledge found in web datasets like RefinedWeb and RedPajama.
- FineWeb-Edu: A refined subset of FineWeb, focused on educational and instructive content. This dataset cleans vast web text into usable, narrative-style educational resources.
- Mint-1T: an open-source Multimodal Interleaved dataset containing 1 trillion text tokens and 3.4 billion images. It introduces new data sources, including PDFs and ArXiv papers. From this dataset, we collected the subset of documents originating from “.gov” sources.
- Cultura-Y: A multilingual gem with contributions from over 70 languages, ensuring diverse cultural and linguistic representation.
- TxT360: A comprehensive dataset that globally deduplicates 99 CommonCrawl snapshots and 14 curated non-web data sources, including FreeLaw and PG-19. It includes approximately 5.7 trillion tokens of high-quality text data. We use the portion of the TxT-360 common crawl that has duplicate signals of 11 or above, meaning that these documents may be more important, since their content has been repeated.
Curated Datasets
- Open License Corpus (OLC): We were heavily inspired by the OLC corpus. This dataset supports domain-specific learning in areas such as law, science, and technology. All data is sourced from permissively licensed material (e.g., CC-BY). We include selected sources across eight domains, including legal texts such as case law (public domain) and the Pile of Law (CC BY-SA subset); arXiv abstracts and subsets of S2ORC (public domain and CC BY-SA); news sources such as public domain news and Wikinews (CC BY-SA); and encyclopedic entries from Wikipedia (CC BY-SA). We collected and further cleaned and reformatted a subset of this collection and/or removed certain citations that are likely too difficult for models to memorize reliably.
- WebSight: The Websights dataset comprises synthetically generated HTML/CSS code representing English websites, each accompanied by a corresponding screenshot. It serves as a valuable resource for tasks such as generating user interface code from visual inputs. We rephrased the WebSights dataset so that it is framed as instructions and responses.
- PG-19: We incorporated data from PG-19, comprising 28,752 books from Project Gutenberg published before 1919. This dataset serves as a valuable resource for training models to capture long-range dependencies in text. We use TXT360’s version of PG-19, and we further created shards of the books that are roughly 4096 tokens.
- Freelaw: Sourced from The Pile, this dataset comprises legal documents which improves the models knowledge about the law.
- StackV1: We included several subsets of the stack v1 dataset, modifying them removing headers to remove duplicate text. We further created a subset by clustering certain portions based on minhash and concatenating similar documents into single examples. Specifically, we flattened the python-edu portion by combining files from the same repository into a single example. Specifically, we included the following programming languages: Antlr, AppleScript, Awk, Batchfile, Clojure, CMake, CoffeeScript, Common Lisp, C/C++, C#, Emacs Lisp, Fortran, Go, Java, JavaScript, Jupyter scripts and structured data, Makefile, Mathematica, Perl, Python, Rust, Scheme, Shell, SQL, Tcl, TypeScript, and Yacc. We also included multilingual code to enhance language diversity. In addition to code, we incorporated non-coding data formats such as Markdown, HTML, and JSON to provide structured documentation.
- Euro-Pat: A parallel multilingual dataset comprising patent documents from the United States Patent and Trademark Office (USPTO) and the European Patent Organisation (EPO). It aligns patents from different countries within the same “family,” providing multilingual context. To further enrich this resource, we have generated synthetic images corresponding to the patent documents.
- USPTO Data: Derived from TXT360 and The Pile and further cleaned for use in Aurora-m1, this dataset provides a comprehensive collection of U.S. patent documents.
- COCO Captions: We recaptioned the coco-2017 dataset, commonly used to develop models for multimodal understanding.
- OIG: We included certain subsets of the OIG dataset, rephrased with a LLM. Specifically, we incorporated the Unified SQL, Unified SKG, Abstract-Infil and Canadian Parliament subset of the OIG dataset.
- Europarl: A parallel corpus sourced from TxT360 extracted from the proceedings of the European Parliament, covering 21 European languages.
- 10-K Filings: A dataset comprises a collection of 10-K filings, which are comprehensive annual reports filed by publicly traded companies to the U.S. Securities and Exchange Commission (SEC). These documents provide detailed insights into a company’s financial performance, risk factors, and management discussions.
- Atticus: A comprehensive, expert-annotated dataset designed for research in legal contract review. It includes over 13,000 annotations across 510 commercial legal contracts, focusing on 41 categories of clauses deemed crucial in corporate transactions such as mergers and acquisitions.
- Aozora Bunko: A digital library that hosts a vast collection of Japanese literary works that are in the public domain. The project aims to make classic Japanese literature accessible to the public by digitizing and providing texts in various formats.
- Hackernews: Sourced from OLC and TxT360, this dataset includes discussions and articles from the Hacker News platform.
- StackExchange: A dataset comprising of publicly available data from the Stack Exchange network, including users’ questions, answers, comments, and associated metadata. We included RedPajamav1’s and TxT360’s Stack Exchange dataset, encompassing a wide range of topics from the Stack Exchange network.
- Openwebmath: An open dataset of high-quality mathematical web text, containing 14.7 billion tokens extracted from mathematical webpages, intended for training language models in mathematical reasoning.
- Wikibooks: A Wikimedia project that offers a collection of open-content textbooks and manuals across various subjects, including computing, science, humanities, and more. The content is collaboratively written and freely available under Creative Commons licenses.
- Pubmed Abstracts: A dataset comprising abstracts from biomedical literature, sourced from PubMed. It includes millions of abstracts detailing research across various biomedical fields. This dataset was obtained from the Pile and TxT360 datasets.
- Pubmed Central: A free digital archive of full-text biomedical and life sciences journal literature. The dataset includes articles made available under licenses that permit text mining and other forms of reuse. It was extracted from the TxT360 dataset.
- NIH ExPorter: A dataset includes administrative data on NIH-funded research projects. It provides detailed information on awarded grants, including abstracts, funding amounts, and project durations. This data was processed from the Pile dataset.
- Elsevier-oa: This corpus comprises over 40,000 open-access articles from Elsevier journals, available under the CC-BY license. It spans a wide range of scientific disciplines, such as medicine, biology, chemistry, physics, and engineering.
- Clap Synthetic Captions: The CLAP dataset provides synthetic captions for audio clips, generated using advanced audio-language models. Includes captions for a large number of audio clips, with each clip accompanied by multiple synthetic captions.
- arXiv Summaries: Sourced from OLC, this dataset includes summaries of research papers from arXiv, facilitating research in scientific literature summarization.
- Wikipedia: We included portions of Wikipedia from TxT360’s subset. To limit non-educational value documents, we filtered out articles about currently living persons, such as sports stars, or shorter articles, including those about sporting events, inspired by Phi-3 and 4’s work. Additionally, we included clustered Wikipedia articles based on minhash clustering for languages: English (en), Italian (it), Polish (pl), Swedish (sv), and Dutch (nl).
- Megawika: A large-scale, multilingual, and cross-lingual dataset containing 30 million Wikipedia passages with their cleaned web citations in 50 languages. We used the original Wikipedia documents, select translations, and .gov web pages in this corpus, cleaning the content, aligning multilingual pairs, and appending relevant .gov webpages cited by Wikipedia. This results in a structured and contextualized knowledge base.
- VALID: Developed by Ontocord.AI in collaboration with Grass and LAION, VALID includes approximately 720,000 Creative Commons-licensed YouTube videos. It combines: Video frames, Audio, Multilingual transcripts. This enables training on rich multimodal interactions, where models learn the interplay between vision, language, and sound. We use only the text portion of this dataset for now.
- Youtube Commons: A collection of over 2 million YouTube videos released under CC-BY, providing 45 billion words of multilingual conversational transcripts. This hopefully will teach models how humans actually talk—across contexts, languages, and cultures. We collapsed transcripts for the same video into a single example so that the multilingual translations are presented together. We also performed text cleanup to remove some grammar and spelling issues.
Synthetic Data
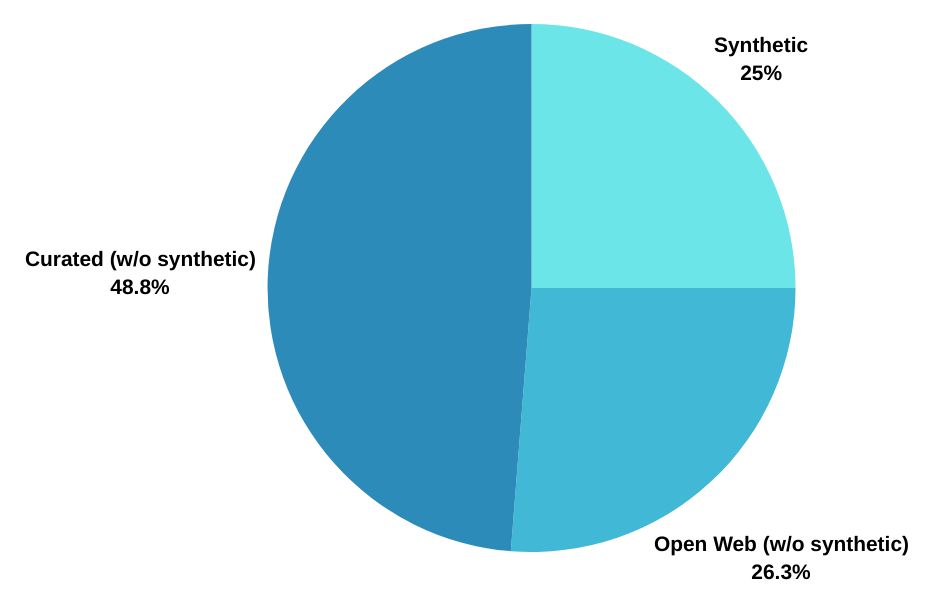
A large portion of our dataset is composed of synthetic data, intertwined and interleaved with organic data. For example, a large portion of our web datasets comes from nemotron-cc which is mostly synthetic data, and we have also curated synthetic translations from sources such as Megawiki. The pie chart in Figure 1 illustrates the distribution of data, where we estimated the proportions excluding synthetic content and grouped all synthetic portions into the Synthetic dataset category.
- Multiple-Choice Question (MCQ) Generation: We generate multiple-choice questions (MCQs) derived from rich knowledge sources such as GenericsKB, as well as abstract infill templates from the OIG dataset. These MCQs are intended to promote the ability to answer multiple choice questions.
- Synthetic Stories: We generated synthetic stories similar to TinyStories, based on datasets like Atomic 2024, and select portions of the PG-19 dataset.
- Mathematical Generation:
- We create math textbooks for specific complex topics by combining mathematical instruction seed data with open-source mathematical web texts. The goal of this dataset is to teach the model about basic math such as arithmetic and algebra.
- We also create synthetic math questions and answers to teach basic math as well.
- Instruction Generation: The instruction generation pipeline creates structured instructions, stories, and data analysis summaries, similar to Ultra-Magpie from SmolLM, but without editing instructions.
Additionally, we include widely-used open source and permissive post-training datasets from Hugging Face, reformatting them into a pretraining corpus by flattening their structures. While these are mostly intended for post-training, we incorporate these datasets at various stages of training to determine if they improve eval metrics. The current set of datasets incorporated are:
- nvidia/OpenMathInstruct-1: A math instruction tuning dataset with 1.8M problem-solution pairs generated using permissively licensed Mixtral-8x7B model. The problems are from GSM8K and MATH training subsets and the solutions are synthetically generated by allowing Mixtral model to use a mix of text reasoning and code blocks executed by Python interpreter.
- ifeval-like-data: This dataset contains instruction-response pairs synthetically generated using Qwen/Qwen2.5-72B-Instruct following the style of google/IFEval dataset and verified for correctness with EleutherAI lm-evaluation-harness.
- Bespoke-Stratos-17k: A dataset comprising 17,000 entries designed for model refinement and evaluation. It includes 5,000 coding-related samples sourced from the APPs and TACO datasets, 10,000 math-focused examples drawn from the AIME, MATH, and Olympiad subsets of the NuminaMATH dataset, and 1,000 science and puzzle problems from the STILL-2 dataset. The dataset is distilled from DeepSeek-R1.
- SystemChat-2.0: A dataset designed for training conversational agents, including system-initiated dialogues across diverse scenarios. It is used to instill strong instruction-following abilities and adherence to system prompts.
- Ultrafeedback_phi3_responses: A subset of the Ultrafeedback dataset containing responses generated by the Phi-3 model. Since the model we are training shares architectural similarities and data characteristics with Phi, this subset is chosen to align closely with our target model’s behavior.
- CaseHOLD_Phi4_Reasoning: A collection of Phi-4 model responses on the CaseHOLD dataset, which focuses on legal case holdings. This dataset supports the development of models with advanced legal reasoning capabilities.
- Magpie Collection: A collection of a set of high-quality instruction datasets generated using the Magpie technique - a self-synthesis approach where aligned language models autonomously create diverse instruction-response pairs. It includes Magpie-Gemma2-Pro-534K-v0.1, containing 534K entries distilled from Gemma-2-27B-Instruct for general alignment and performance; Magpie-Phi3-Pro-1M-v0.1, with 1 million professional-grade samples distilled from microsoft/Phi-3-medium-128k-instruct for advanced instruction tuning; and Magpie-Qwen2.5-Coder-Pro-300K-v0.1, comprising 300K code-focused samples distilled from Qwen2.5-Coder-32B-Instruct for code generation tasks.
- DeepScaler-QwQ_32b: A specialized collection derived from the DeepScalerR dataset, comprising 20,000 samples. Each sample includes a question and its corresponding answer generated by the Qwen/QwQ-32B model, which is designed for advanced reasoning tasks such as mathematics and coding.
- SYNTHETIC-1: A reasoning-focused dataset distilled from DeepSeek-R1 and annotated with a diverse set of verifiers, including LLM-based judges and symbolic mathematics verifiers. It includes a wide range of challenging tasks, such as competition-level math problems from NuminaMath, coding problems from platforms like LeetCode, and curated datasets including APPS, CodeContests, Codeforces, and TACO. It also includes problems derived from real-world GitHub commits via the CommitPack dataset, as well as questions sourced from the StackExchange dataset.
- MetaMathQA-R1: S text dataset designed to train LLMs with DeepSeek-R1 level reasoning. The prompts in this dataset are derived from the training sets of GSM8K and MATH, with responses generated directly by DeepSeek-R1. OpenR1-Math-220k: A large-scale dataset for mathematical reasoning. It consists of 220k math problems with two to four reasoning traces generated by DeepSeek R1 for problems from NuminaMath 1.5. The traces were verified using Math Verify for most samples and Llama-3.3-70B-Instruct as a judge for 12% of the samples.
- OpenManus-RL: Combines agent trajectories from AgentInstruct, Agent-FLAN, and AgentTraj-L (AgentGym) with key features including the ReAct prompting framework, structured training (separate format and reasoning learning), and anti-hallucination techniques (negative samples and environment grounding). Covers six domains: Operating Systems, Databases, Web, Knowledge Graphs, Household, and E-commerce.
Overall, the datasets is composed of roughly 20-30% synthetic data, with that percentage growing after we have completed translations and additional multimodal generation. We expect that a major portion of MixtureVitae will then be synthetic.
How Do We Filter Web Based Data?
Permissive filtering
We performed a “pseudo-crawl” of the “open web dataset” for .gov and similar websites. And we also searched for the keywords “CC-BY-SA” and similar keywords and heuristics. We also performed removal of documents with spam like keywords in English, and a high proportion of obscene or offensive words or child sexual abuse materials (CSAM) words in multiple languages.
Dedup and heuristic filtering
Then we perform a global deduplication (across web based documents) of these sources using only a prefix based matching of the documents. This is because the source datasets have been already deduplicated, so we perform only light global deduplication. We then remove common ngrams that begins or ends documents as these are sometimes generic headers such as “Home | Search” etc. We find sentence duplicates and remove these if they have low proportions of stopwords, as we find these are likely uninformative text. We augment other sentence duplicates using a wordnet synonym substitution method. We also perform filtering of documents with high proportions of obscene words, adult content and content involving minors and sexual abuse.
Fasttext Filtering
One of the challenges of .gov web data is that it can skew heavily toward regulatory or compliance-heavy content, leading to overrepresentation of certain tones or subject matter. To avoid a narrow, one-note model, we implemented genre and domain balancing — a process that boosts the proportion of diverse and underrepresented content types.
Classification. We implemented multi-layered FastText classifiers to give us more insight into our data and to enable us to sample diverse subsets.
- Domain Classification: We used data from FineWeb which categorizes text based on a standard set of taxonomies. This dataset was used to train a fastText classifier, which we then used to classify a large portion of our text. We use this model to classify a large portion of our text.
- Classification Based on Pile Type: We developed a fastText classifier to identify and categorize content from various sources present in the Pile dataset. The categories follows the sources in this dataset, including Pile-CC, PubMed Central, Books3, OpenWebText2, ArXiv, Github, FreeLaw, Stack Exchange, USPTO, Backgrounds, PubMed Abstracts, Gutenberg (PG-19), OpenSubtitles, Wikipedia (en), DM Mathematics, Ubuntu IRC, BookCorpus2, EuroParl, HackerNews, YoutubeSubtitles, PhilPapers, NIH ExPorter, and Enron Emails. Note that we do not actually include most of these datasets from the Pile due to copyright concerns. Rather, we have classified our permissive text to help us decide on how to maintain diversity across domains. This classifier produces a lower quality signal, but we include this for researcher’s usage.
- Register (Genres): We employ TurkuNLP’s FastText classifier to give us insight into the different registers (genres) in our dataset, ultimately allowing us to appropriately balancing types of contents. The classifier covers a wide array of web text styles, including Narrative, Informational Description, Opinion, Interactive Discussion, How-to/Instruction, Informational Persuasion, Lyrical, and Spoken. This classification draws from the TurkuNLP annotation framework, which identifies text purpose (e.g., to narrate, instruct, describe, persuade, or express opinion), to identify diverse genres sources like blogs, news reports, Q&A forums, and instructional content.
- Limitations. At present, our classifiers are mainly English based and do not classify well non-English text.
Ranking. We also implemented multi-layered FastText classifiers to rank documents for quality data.
- Mathematics Ranker: To enhance mathematical reasoning, similar to DeepSeekMath, a fastText classifier is trained to recall mathematics text from the web. Our initial model uses 800,000 samples from MiniPile, which represents a diverse subset of Pile as negative class, and 800,000 samples from openwebmath as positive class. However, as we observe the initial classifier is not sensitive to latex mathematical symbols, and also inspired from DataComp-LM, we include instruction-format data drawing from StackMathQA, OpenR1-Math-220k, MetaMathQA and Omni-MATH, and downsample openwebmath to maintain balance class.
- Red Pajama Ranker: We use RedPajamas’s fastText classifier, which provides signals if a text is similar to content in websites referenced by Wikipedia.
- Educational Value Ranker: Inspired by Textbooks are All You Need, we use an open source educational value classifier to recall content with high educational value from the web. Its training data is constructed by employing Phi-3-mini-128k-instruct to annotate MiniPile with educational value.
- Limitations. At present, our rankers are mainly English based and do not rank well non-English text. The ranking uses an ensemble method to assess the quality of web documents. This approach combines multiple scoring metrics to determine an overall quality score for each document. Notably, we rank web based documents including synthetic documents associated with web data such as MAGACorpus and nemotron-cc, and do not rank documents from curated sources such as PG-19, The Stack v1, Wikipedia, Stack Exchange, etc., recognizing their established quality and relevance. We use an average score of High Quality Content Score, the Educational Score and Math score to create a Quality score. For high quality documents, our threshold is 0.3. Additionally for Math documents, we also consider documents that might fall below 0.3, but has a math score about 0.8.
How Do We Filter Curated Data?
While curated data such as code data from the Stack v1 and Wikipedia are generally of medium to high quality, we perform further processing to improve the quality of the data. Since we multiple sources for the same data (e.g., Stackexchange from both TxT360 and RedPajama v1), we perform a deduplication within subsets. For all datasets, we filter documents that have high proportions obscene or adult content and content involving minors and sexual abuse. We found that some documents include base64 encoded text which can confuse models, and thus we filtered out these documents. For Wikipedia based documents, we filtered documents that are mainly about films, sporting events, and biographies of living persons. This was inspired by filtering techniques in Phi-3.
Our Position For Using Governmental Works
Our ethical and legal reasoning for using government web content—sourced from Common Crawl-related datasets—is as follows:
- Public Purpose Alignment: The content created by governments is normally meant to be shared with the public, and by using the data for training we are assisting this purpose.
- Purpose of Use: From a legal perspective, the government works are being redistributed as part of an open source, no-fee dataset to be used to create models are less likely to be copyright violating. This purpose is clearly not to compete with the government’s own usage.
- Effect on Potential Market: We also think it is more likely to be fair use because the use of government website content is unlikely to have an effect on the potential market for the government’s website content because the government is unlikely to be making commercial use of the content.
- Nature of the Content: The nature of the content is mostly public announcements, content of public interest, governmental functions or the like. Again, we believe there is strong public policy interest for fair use of this type of information.
- Amount Used: While we use all or almost all of the content of the government website, the amount of usage is not determinative of fair-use or not fair-use.
- Federal vs. Non-Federal Works: Lastly, US works created by the federal governments are generally not copyrightable. However, we recognize that this is not the case for other foreign governmental works, or non-federal works.
For these reasons, we believe using government website data is lower copyright risk. But, to minimize the risk further such as the potential inclusion of third party copyrighted works on government web-pages, we have included keyword filters such as “All Rights Reserved”, “Copyright ©”, etc. to further filter out government web pages that have these terms.
With that said, we do not and cannot guarantee that even with rigorous provenance tracking and standard filtering, that there is no copyright issues, so we recommend anyone who uses our datasets to consult their own attorney in their jurisdiction.
This is an evolving blog, so check back in from time to time to get updates and welcome to our journey!
Citation
@misc{mixturevitae_2025,
author = {Huu Nguyen, Harsh Raj, Ken Tsui, Minh Chien Vu, Sonny Vu, Diganta Misra, Victor May, Marianna Nezhurina, Christoph Schuhmann, Robert Kaczmarczyk, Andrej Radonjic, Jenia Jitsev},
title = {MixtureVitae: A Permissive, High-Performance, Open-Access Pretraining Dataset},
howpublished = {https://aurora-lm.github.io/posts/mixturevitae},
note = {Accessed: 2025-04-12},
year = {2025}
}