Branch Train Stack (BTS) For the Aurora-M2 Pretrained Models
By: Huu Nguyen, Harsh Raj, Ken Tsui, Minh Chien Vu, Felix Friedrich, Sonny Vu, Diganta Misra, Marianna Nezhurina, Victor May — Apr 28, 2025
Huggingface: Aurora-M2
Introduction
For training Aurora-M2, we introduce a novel Phased Training approach that is highly efficient in terms of compute requirements while offering a simple process for debugging and data preparation throughout the training process.
Phased Training
We are adopting a phased approach to training. Our strategy for AuroraM-2 aims to achieve multiple objectives simultaneously: high data quality, expert specialization, and scalable performance across various parameter regimes (3B, 8B, and 20B), all while using significantly less compute than conventional large-scale models.
We propose a novel training scheme optimized for low-resource environments and infrastructures with limited inter-node connectivity. As the proverb goes, necessity is the mother of invention; we devised this process to address our compute constraints. This approach, which we call Branch-Train-Stack (BTS), is inspired by prior work from Meta AI but introduces key innovations tailored for our context.
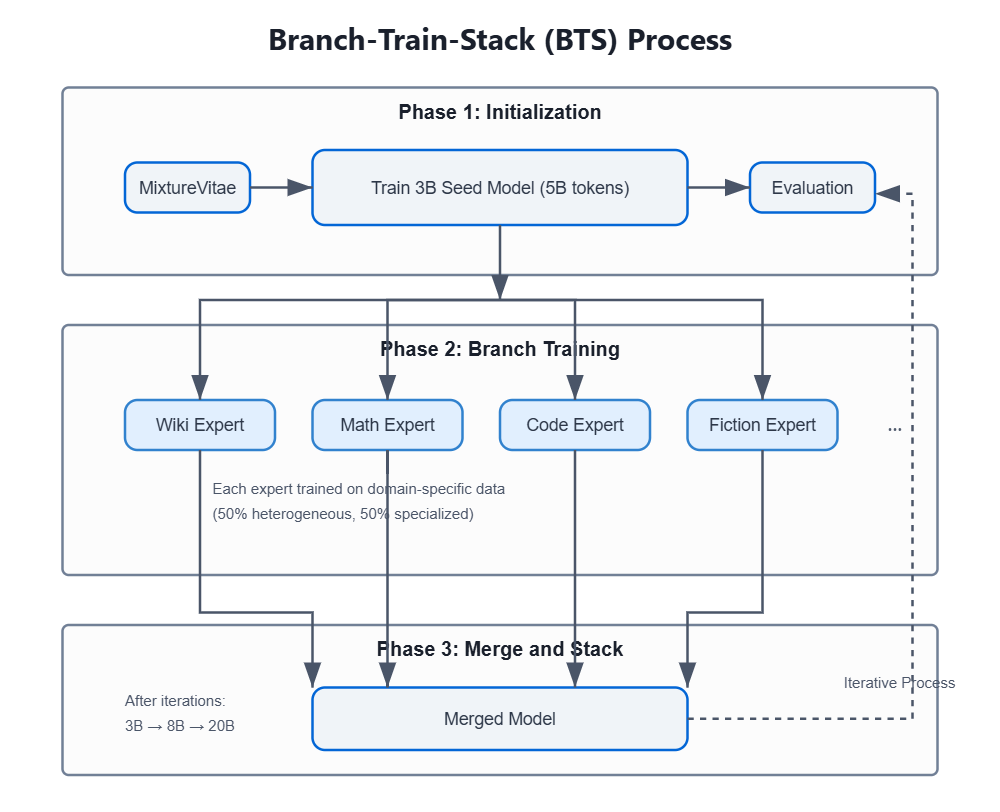
The Branch-Train-Stack Process
The process can be broken down into several key stages:
Initialization
In our previous blog we collected the dataset, MixtureVitae: A Permissive, High-Performance, Open-Access Pretraining Dataset. We sample chunks from this dataset across our training process.
Our process begins with training an initial seed model—a 3-billion-parameter model initialized from scratch based on the Qwen2.5-14B architecture, with decreased number of layers to produce a 3B model. We sample roughly 5 billion heterogeneous tokens from MixtureVitae to serve as the base dataset for the seed model. Early experiments involve training several mixtures derived from MixtureVitae and evaluating them to select the best-performing model. For initial validation, we utilize 5 billion tokens for training at each stage. However, the training pipeline has been scaled to accommodate 20 billion tokens per iteration per expert.
Inspired by prior works and the use of instructions in pretraining as in this work and our prior Aurora-M1 models, we perform alignment during pretraining to instill desired behaviors early, rather than only addressing misalignments during post-training. We observe that simply injecting refusals early in the training process will create undesirable behaviours, so we have instead created pro-social reasoning traces to inject alignment instructions. Specifically, we use an in-house data synthesis pipeline to create synthetic instructions that incorporate EU AI Act policies into the model. Our targeted data generation pipeline allows us to adjust the data mix to focus on areas where the student model underperforms, thereby improving performance. This novel data synthesis pipeline generates data from scratch in a fully controlled way; we discuss it in more detail in our AutoRedTeam blog.
Branch-Train-Stack
In our initial experiments, we first train a seed model on 5B tokens. Then we branch the training into 8 specialized expert models, each initialized from the base model. For our final training experiment, we plan to use 20 experts, with curated data spanning 20 diverse categories. These models are trained separately on domain-specific datasets (e.g., business, fiction, math, medical/health), with a data composition of 50% heterogeneous data and 50% expert-specific data.
Within the heterogeneous portion, we intentionally repeat some data from earlier training stages to minimize unexpected distribution drift. While these numbers were chosen for the initial test, we are still experimenting with the ratio and repetition rate for training. The training is conducted independently for each expert model, ensuring specialization without intercommunication between branches. This approach significantly reduces compute requirements and the need for high-speed inter-node communication between large node clusters.
After training, all eight models are merged to form a new base model. Inspired by state-of-the-art work, we employed the DARE-TIES merging algorithm with a density of 0.9 and assigned a weight of 0.05 to each merged model. While we initially chose equal weighting for each expert, we plan to conduct further ablation studies to optimize these parameters. This iterative process is repeated, progressively refining the model by integrating both general and specialized knowledge over multiple training cycles. Additionally, each expert’s weights can be used to create an MoE as described below.
When scaling to larger models, we adopt a progressive stacking approach. After the N iterations — we perform the first stacking, creating an 8-billion-parameter model. This stacking process is derived from previous works on model stacking. We tested the models through this process and the results are promising.
In our final training phase, we plan to train each expert on 20 billion tokens during each iteration. We will stack the 3-billion-parameter model after 15 iterations of BTS to create an 8-billion-parameter model, and then stack again after 4 more iterations to create a 20-billion-parameter model, and then train for one more iteration.
We will then use the known methods of sparse upcyling to create additional mixture of experts (MoE) models from the various experts we trained. See the BTX methdology which is another architecture that inspired our work.
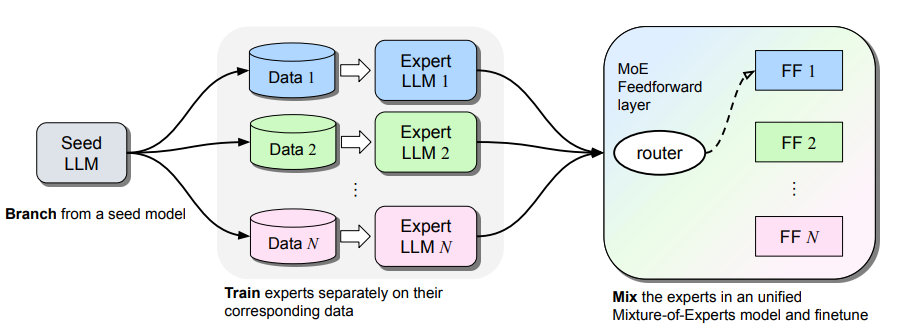
Thus the goal is to train large models of up to 20B active parameters, while using a fraction of the compute - the gains coming from the BTM and stacking method. Additionally, similar to the BTX architecture, the experts can be used as MoE layers, thus creating models of > 200B parameters. This work, is to the best of our knowledge the first combination of known methods for efficient training - BTM -> BTX -> Stacking, which will produce efficiently trained and high performing models.
Preliminary Results
We conducted a series of ablation studies to assess the viability of our proposed training scheme. For the preliminary experiments and validation, we only used 5B training tokens at each stage. Table 2 presents the results from the initial phase and the expert phase up to two iterations, including the outcomes of the stacking model after these iterations. All evaluations were performed using Hugging Face’s Lighteval framework, with the exception of HumanEval, which was done using BigCodeBench.
| Stage | Expert | HumanEval (pass@100) | GSM8k (lm_eval) | ARC Challenge | Winogrande | MMLU | Hellaswag |
|---|---|---|---|---|---|---|---|
| 0 | init | 0 | 0.0235 | 0.2448 | 0.5067 | 0.2543 | 0.2966 |
| 1 | wiki | 0 | 0.0243 | 0.2448 | 0.5082 | 0.2542 | 0.2964 |
| 1 | formatted_text | 0 | 0.0288 | 0.2474 | 0.5161 | 0.2499 | 0.3123 |
| 1 | how_to | 0.0223 | 0.0152 | 0.2457 | 0.4932 | 0.2468 | 0.3342 |
| 1 | law | 0.0219 | 0.0182 | 0.2542 | 0.4988 | 0.2556 | 0.3105 |
| 1 | news | 0.0304 | 0.0121 | 0.2482 | 0.5051 | 0.2545 | 0.3156 |
| 1 | software | 0.0162 | 0.0212 | 0.2372 | 0.5177 | 0.2524 | 0.3068 |
| 1 | fictional_lyrical | 0.0115 | 0.0182 | 0.2525 | 0.5114 | 0.2478 | 0.3147 |
| 1 | math | 0.0805 | 0.0356 | 0.2602 | 0.5098 | 0.2587 | 0.3154 |
| 1 | merged | 0.0558 | 0.0182 | - | - | - | - |
| 2 | fictional_lyrical | 0 | 0.0174 | 0.2576 | 0.5177 | 0.2446 | 0.324 |
| 2 | math | 0.0758 | - | 0.25 | 0.509 | 0.2546 | 0.3143 |
| 3 | math_stacked | 0 | - | 0.2542 | 0.5059 | 0.2531 | 0.3202 |
Table 2: Preliminary results of BTS training across different phases and experts.
We experimented to confirm if branch train and merging was effective. We find that indeed after merging the model does not forget it’s previous skills. We also tested to see if stacking would have an adverse effect. As noted in the literature, stacking initially decreases performance but not substantially. The model’s performance should recover and improve with additional training.
For evaluation, we selected tasks commonly used for assessing small language models, such as those employed in SmolLM evaluations. These tasks are relatively less complex than current standards, providing early indicators of improvement during initial training stages. At this early stage, we do not anticipate the model to have acquired extensive world knowledge or factual information, as such competencies typically require more extensive training.
However, we expect evaluation results for math and code tasks to show an increasing trend, as these are relatively logic-oriented tasks rather than reliant on memorization. This expectation aligns with our observed results. The results indicate that our pipeline is effective, showing improvements in model scores, particularly for logic, code, and math-related tasks—areas often considered primary indicators of learning progress.
Conclusion
The Branch-Train-Stack (BTS) approach offers a promising and efficient method for training large language models with limited computational resources. By leveraging specialized expert models and progressive scaling, we can build powerful models that perform well across various parameter regimes while maintaining high quality and efficiency.
Our preliminary results demonstrate the effectiveness of this approach, and we continue to refine and optimize our training process. Stay tuned for more updates as we progress through our training phases and reach our final 20B model.
Looking forward, we foresee more optimization opportunities in improving the serving performance. For instance, DeltaMoE proposes compressing the deltas in each expert, leading to improved efficiency and performance. We believe that BTS has the potential to deliver benefits not only in training but also in the efficient deployment and serving of large models.
Citation
@misc{bts_aurora_2025,
author = {Huu Nguyen, Harsh Raj, Ken Tsui, Vu Minh Chien, Felix Friedrich, Diganta Misra, Victor May, Marianna Nezhurina},
title = {Branch Train Stack (BTS) For the Aurora-M2 Pretrained Models},
howpublished = {https://aurora-lm.github.io/posts/bts-aurora-m2},
note = {Accessed: 2025-04-28},
year = {2025}
}